Summary: in this tutorial, you will learn how to use the PostgreSQL SELECT DISTINCT clause to remove duplicate rows from a result set returned by a query.
Introduction to PostgreSQL SELECT DISTINCT clause
The SELECT DISTINCT removes duplicate rows from a result set. The SELECT DISTINCT clause retains one row for each group of duplicates.
The SELECT DISTINCT clause can be applied to one or more columns in the select list of the SELECT statement.
The following illustrates the syntax of the DISTINCT clause:
SELECT
DISTINCT column1
FROM
table_name;Code language: SQL (Structured Query Language) (sql)In this syntax, the SELECT DISTINCT uses the values of the column1 column to evaluate the duplicate.
If you specify multiple columns, the SELECT DISTINCT clause will evaluate the duplicate based on the combination of values in these columns. For example:
SELECT
DISTINCT column1, column2
FROM
table_name;Code language: SQL (Structured Query Language) (sql)In this syntax, the SELECT DISTINCT uses the combination of values in both column1 and column2 columns for evaluating the duplicate.
Note that PostgreSQL also offers the DISTINCT ON clause that retains the first unique entry of a column or combination of columns in the result set.
PostgreSQL SELECT DISTINCT examples
Let’s create a new table called distinct_demo and insert data into it to practice the DISTINCT clause.
Note that you will learn how to create a table and insert data into it in the subsequent tutorial. In this tutorial, you need to execute the statement in psql or pgAdmin to execute the statements.
First, create the distinct_demo table that has three columns: id, bcolor and fcolor using the following CREATE TABLE statement:
CREATE TABLE distinct_demo (
id SERIAL NOT NULL PRIMARY KEY,
bcolor VARCHAR,
fcolor VARCHAR
);Code language: SQL (Structured Query Language) (sql)Second, insert some rows into the distinct_demo table using the INSERT statement:
INSERT INTO distinct_demo (bcolor, fcolor)
VALUES
('red', 'red'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue'),
('green', 'red'),
('green', 'blue'),
('green', 'green'),
('blue', 'red'),
('blue', 'green'),
('blue', 'blue');
Code language: SQL (Structured Query Language) (sql)Third, retrieve the data from the distinct_demo table using the SELECT statement:
SELECT
id,
bcolor,
fcolor
FROM
distinct_demo;Code language: SQL (Structured Query Language) (sql)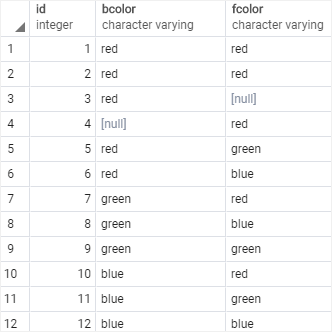
PostgreSQL DISTINCT one column example
The following statement selects unique values in the bcolor column from the t1 table and sorts the result set in alphabetical order by using the ORDER BY clause.
SELECT
DISTINCT bcolor
FROM
distinct_demo
ORDER BY
bcolor;Code language: SQL (Structured Query Language) (sql)
PostgreSQL DISTINCT multiple columns
The following statement demonstrates how to use the DISTINCT clause on multiple columns:
SELECT
DISTINCT bcolor,
fcolor
FROM
distinct_demo
ORDER BY
bcolor,
fcolor;Code language: SQL (Structured Query Language) (sql)
Because we specified both bcolor and fcolor columns in the SELECT DISTINCT clause, the statement combined the values in both bcolor and fcolor columns to evaluate the uniqueness of the rows.
The query returns the unique combination of bcolor and fcolor from the distinct_demo table.
Notice that the distinct_demo table has two rows with red value in both bcolor and fcolor columns. When we apply the DISTINCT to both columns, it removes one duplicate row from the result set.
Summary
- Use
SELECT DISTINCTto remove duplicate rows from a result set of a query.